最近发现使用WSL非常方便。不仅可以不用实体机器安装Linux,同时也可以避免额外的浪费空间。因此打算部署一个局域网内的个人知识库体系,这样就可以建立一个强大的知识和大模型体系,真正用到AI的能力。 访问 个人技术博客: fuqifai.github.io
本文大部分配图使用微信小程序【字形绘梦】免费生成。
AIGC技术讨论群

首先安装WSL 安装WSL,一般的教程是直接用管理员打开CMD或者PowerShell,执行命令 Wsl –install
以下必要的配图,都使用一款微信小程序【字形绘梦】免费生成。

但是实际上不仅会碰到很多问题,同时你也想更清楚的知道自己要安装什么Linux,版本是什么,能不能安装等问题
-
首先,我们使用下面的命令,确保网络通常,看下自己的机器目前能安装什么样的版本和系统。 WSL –list –online 列出可以装的版本
-
其实执行下面的命令,指定具体的产品,开始安装 WSL –install -d 指定上述一个版本进行安装 或者这样 wsl –install -d Ubuntu-22.04
如果出现错误:
无法启动服务,原因可能是已被禁用或与其相关联的设备没有启动
解决方法: 开启Windows Update , 打开【启用和关闭windows功能】,勾选以下几个服务。重启电脑

同等作用的方法,如果有组件没有安装,可以在Console中以管理员身份执行脚本,开启 适用于 Linux 的 Windows 子系统 dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart 虚拟机平台 dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
其次安装Docker Linux安装好后,虽然说是默认没有安装docker,但是大部分版本目前都自带包含了。 当然如果没有,则执行sudo apt-get install docker-ce 进行安装
Docker下安装AnythingLLM AnythingLLM是个不错的个人知识库,当然也可以应用到企业级别 官方安装文档入口: https://docs.anythingllm.com/installation-docker/overview
本地部署Docker版本地址:https://docs.anythingllm.com/installation-docker/local-docker
官网提供单机版本和Docker版本,两者的差异 (我们目前想要支持多用户在局域网使用,因此使用Docker部署方式) 暂时无法在飞书文档外展示此内容
官方的说法,执行
docker pull mintplexlabs/anythingllm
但可能由于是源的问题,从来没成功过。
我们下载了这个镜像,加载使用 sudo docker load -imyImage.docker 以这种方式可以在任何本地,甚至没有连网的机器上安装该组件。
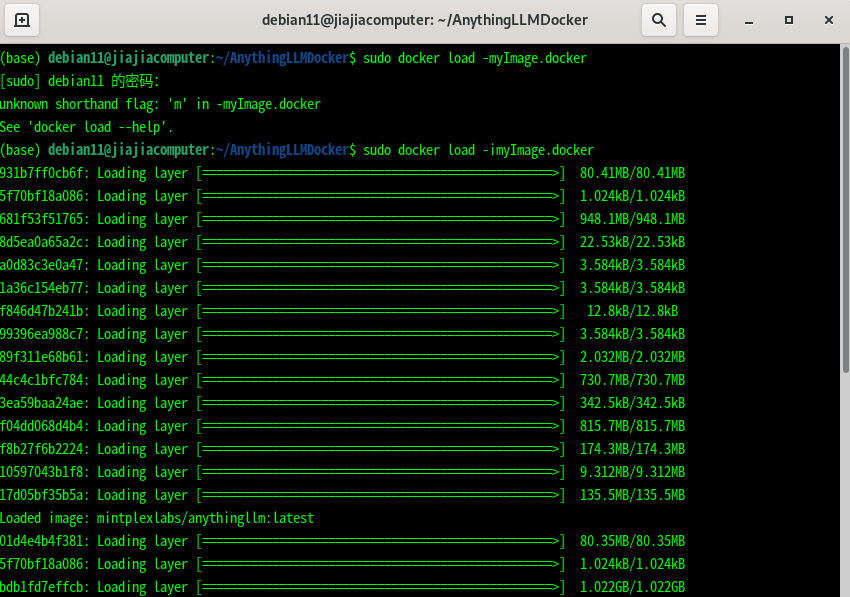
安装好后,需要设置环境和运行Docker 在Terminal中执行下面的命令,首先是设置环境变量,后面是运行Docker命令,可以看到指向3001端口
export STORAGE_LOCATION=$HOME/anythingllm &&
mkdir -p $STORAGE_LOCATION &&
touch “$STORAGE_LOCATION/.env” &&
docker run -d -p 3001:3001
–cap-add SYS_ADMIN
-v ${STORAGE_LOCATION}:/app/server/storage
-v ${STORAGE_LOCATION}/.env:/app/server/.env
-e STORAGE_DIR=”/app/server/storage”
mintplexlabs/anythingllm
注意: 有时候安装不成功,可能是权限问题。 执行这句话的时候,其中的STORAGE_LOCATION/anythingllm 目录,需要sudo chmod 777 anythingllm这样。确保该目录可写。
安装好后,访问http://127.0.0.1:3001 这个地址看到界面就算是成功部署了。 然后新建管理用户,一步步按照页面指示设置内容。在大模型设定这块有坑。Docker版本不像桌面版本那样内置大模型能力,需要自行制定,我们目前使用本地部署的Ollama框架。
Docker下安装Ollama大模型框架
- 用管理员身份命令行执行
curl -fsSL https://ollama.com/install.sh | sh
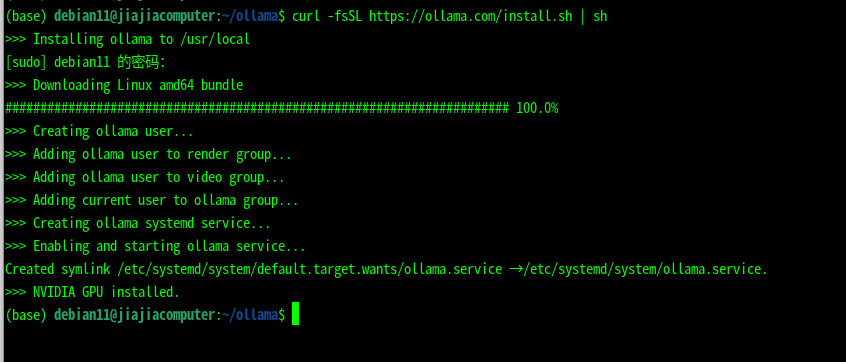
- 打开浏览器 ,访问 http://localhost:11434/ 见到内容就算成功了。
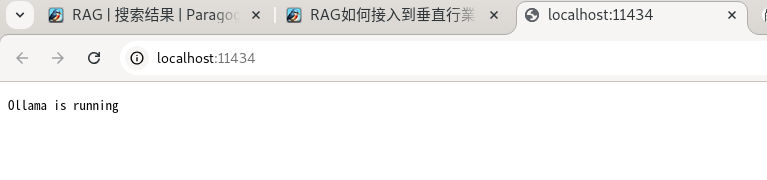 你可以尝试使用Ollama自带的很多命令查看运行情况。
你可以尝试使用Ollama自带的很多命令查看运行情况。
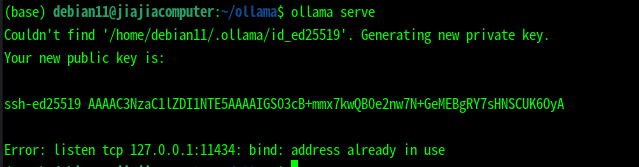
这个是服务已经在运行了。 Ollama实际上还需要下载能用的大模型, 下载大模型 比如执行: ollama run qwen2:7b-instruct-q4_0 或者有时候必须要用到最新的,ollama run llama2 或者最新的模型
Ollama模型下载后的位置
macOS: ~/.ollama/models
Linux: /usr/share/ollama/.ollama/models
Windows: C:Users
让Docker下能访问 让Ollama能给我们刚才部署的Docker下的知识库访问到,需要修改地址。 Ollama默认只允许127.0.0.1:11434访问,我们可以修改配置,让所有IP都可以访问 修改文件/etc/systemd/system/ollama.service , 在[Service]这块最下面新增 Environment=”OLLAMA_HOST=0.0.0.0” 保存,重启Ollama服务即可(Ollama Serve)
AnythingLLM中配置使用Ollama大模型 在AnythingLLM的设置菜单中, 我们按照下图一样的设定,才能让LLM的能力正常运转起来。
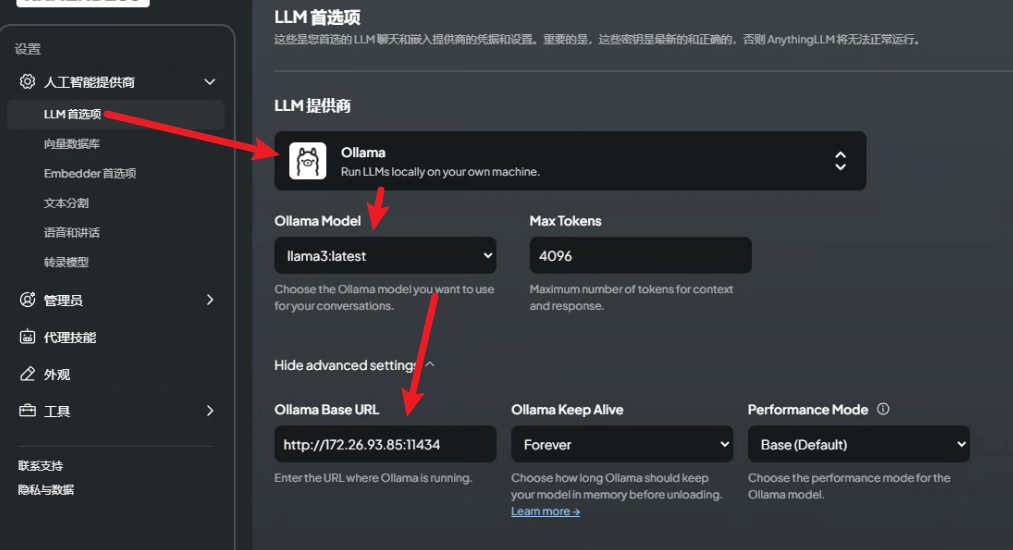
在上图中Ollama Base URL 记得写Http 同时不要使用127.0.0.1这样的本机地址,即便是本机,也用本机的真实IP来代替。 同时,如果配置不正确,或者没有下载好Ollama的大模型,在OllamaModel这个下拉列表中是不出现内容的,此时LLM整体功能也是不可用的。 这里的界面设定不是特别好,用户开始用会觉得好差。
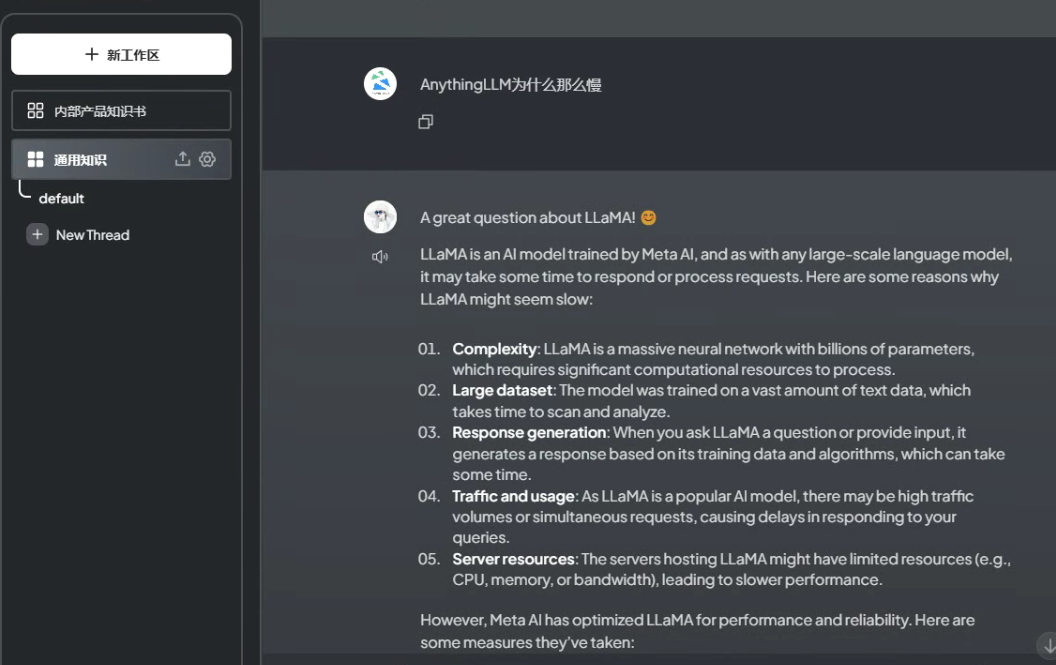
最终使用示意 最后所有的配置都没有问题,在界面上创建工作区。 这个工作区的设定有一些累赘,但是也有些作用,每个工作区可以上传嵌入不同的本地文件数据,从而实现RAG。 不知道为什么AnythingLLM本地部署的RAG能力,嵌入数据文件时非常非常慢。 或许是开源版本和企业版本的区别吧。如下图示意,我们已经可以使用起来知识库了。总结下有以下几个亮点
- 独立自主的大模型能力,还带更新功能
- 独立的知识库体系,具备更新功能
- 局域网本地部署,灵活高效,成本低
- 支持多用户,像一个简单的企业内部应用。